Rst2HTML: waar/hoe de gegevens worden opgeslagen
De eerste versie van deze applicatie gebruikte fysieke bestanden in het bestandssysteem van de server machine, op plekken die in de instellingen gedefinieerd konden worden. Dit is nog steeds de basisversie maar een beetje vereenvoudigd: de "mirror" instelling geeft een root directory ergens op de server waarin ook de source en de target tree hangen. De "url" instelling mapt deze root op een web address zodat a) je de resulterende site meteen kunt bekijken in de webbrowser en b) css files die hier neergezet worden ook in de preview modes kunnen worden gebruikt. Deze mapping correspondeert met hoe de site is geconfigureerd voor de lokale web server.
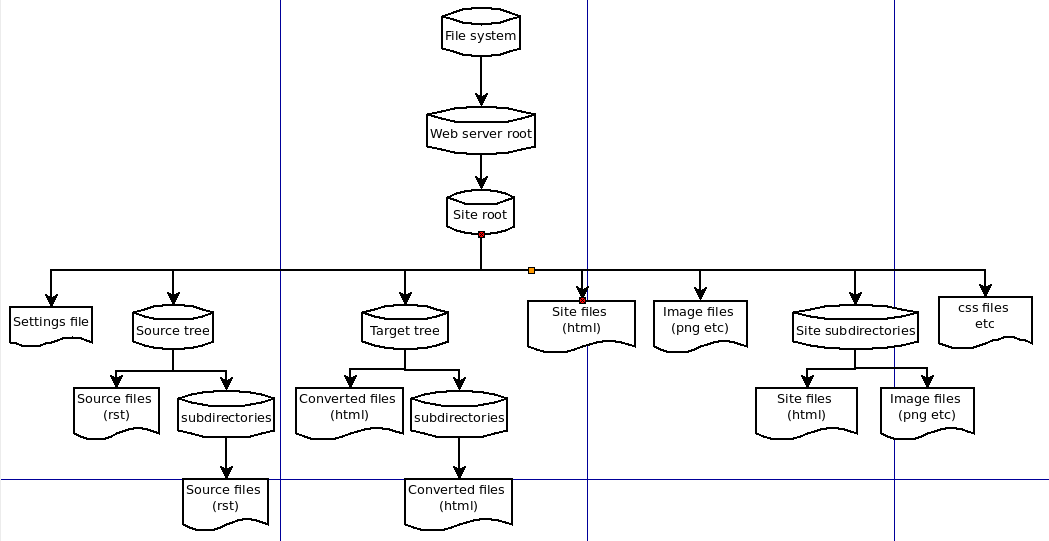
In het linker gedeelte van dit plaatje zie je de opslag van de omzetter: de site settings en de source en target trees. Aan de rechterkant staat het zichtbare gedeelte: de mirror tree met de site documenten en de image en css files die ze gebruiken.
MongoDB
Als oefening om de dataverwerking los te weken van het bestandssysteem bedacht ik een manier om de source en target trees samen met de administratieve gegevens en de site settings onder te brengen in een database. Ik heb daarvoor een NoSQL (MongoDB) database gebruikt, omdat ik daar nog nooit wat mee gedaan had en omdat het me wel een logische keuze leek (onbeperkt lange teksten opslaan in een SQL database voelt voor mij toch een beetje raar). De mirror tree staat nog wel fysiek op de server, op een standaard locatie. De "mirror" and "url" instellingen vervullen hiervoor dezelfde functie als bij de file system versie.
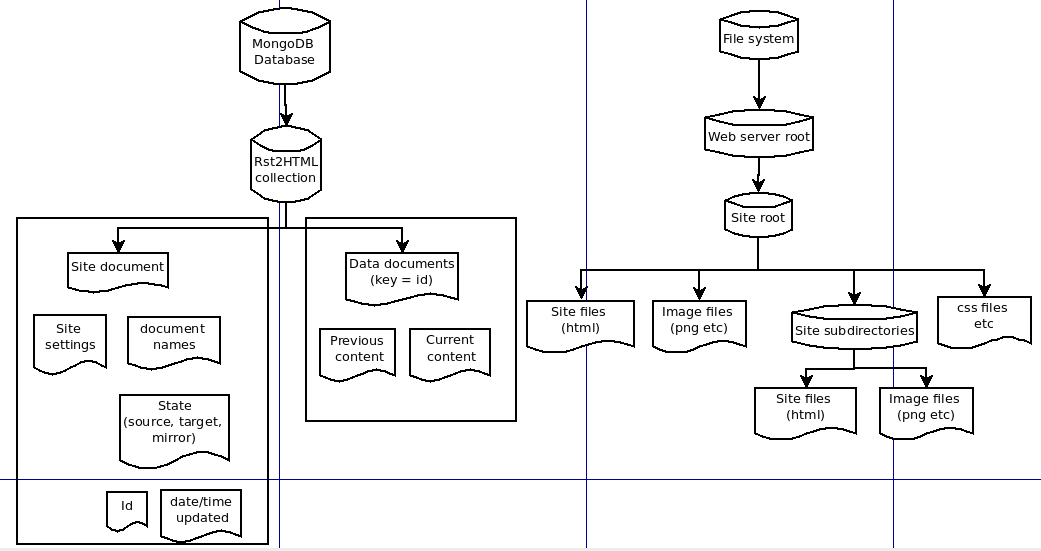
Ook hier staat het data gedeelte aan de linkerkant: documents worden nu opgeslagen als eenheden met als identificatie een subdirectory/filenaam (zonder extensie), deze bestaan uit drie onderdelen (source, target and mirror) met elk een document id en een datum/tijd stempel; de document ids verwijzien naar aparte eenheden die de huidige en de vorige versie bevatten van de specifieke document teksten. aan de rechterkant blijft de structuur van het zichtbare gedeelte van de site hetzelfde.
SQL
Ik heb ook nog een manier bedacht om dit te doen met een SQL database, in dit geval PostgreSQL (want dat was op dat moment ook nog nieuw voor mij). Het mirror gebeuren werkt net als bij de NoSQL versie.
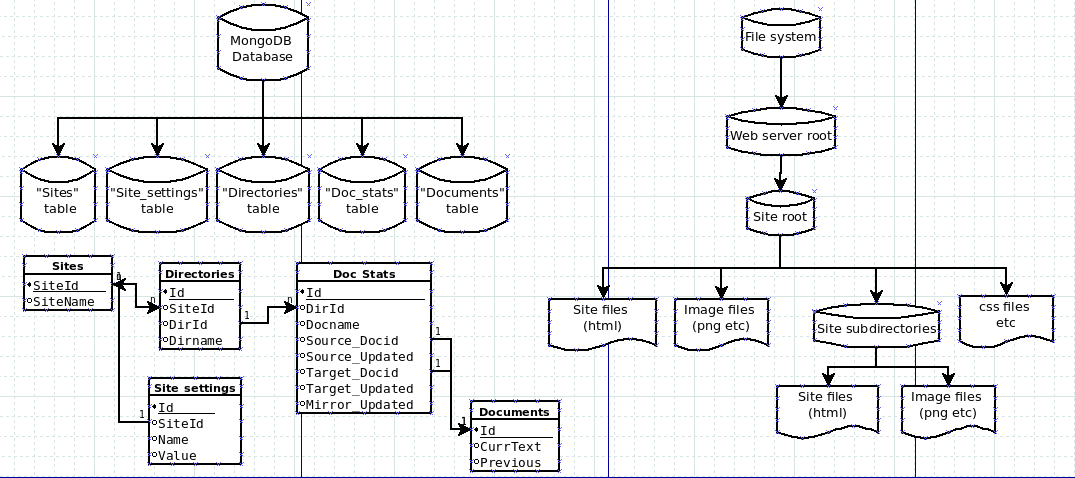
Aan de linkerkant staat hier het database ontwerp om de relaties tussen de tabellen te verduidelijken.
Lagenmodel
Om dit allemaal mogelijk te maken heb ik de code gereorganiseerd zodat er nu vier lagen in zitten. Een dunne UI schil bevat de web views die niet veel meer doen dan een methode aanroepen van een "state" klasse; deze methoden roepen op hun beurt verwerkingsfuncties aan die de uiteindelijke data manipulatie routines aanroepen.
De middelste twee lagen zitten samen in één source file; de buitenste twee zitten in aparte sources om zo ook uitwisseling van buitenlagen mogelijk te maken (niet dat ik voor de UI al een alternatief heb gemaakt - maar het zou moeten kunnen).
Bepalen welke data implementatie er gebruikt wordt kan met de DML instelling in een bestand genaamd app_settings.py. Hierin zit ook een setting genaamd WEBROOT om aan te geven waar de basis location voor de mirror trees zit.
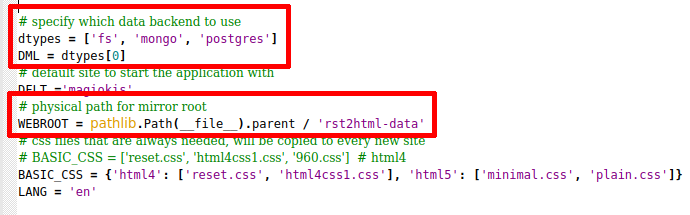
Deze manier van configureren maakt het mogelijk om verschillende webroots voor verschillende data backends te definiëren.